
 By Rahul Sharma, CEO, HSBlox
By Rahul Sharma, CEO, HSBlox
Twitter: @RS_HSBlox
Healthcare is continuing to accelerate its path to value-based care (VBC) models where pay-for-value programs are supplanting the traditional volume-based fee-for-service system.
However, VBC is not a miracle payment model that can automatically transform a healthcare organization, never mind an entire industry. No matter what reimbursement model is used, the key to improving quality, reducing costs, reducing inequities, and increasing healthcare coverage and access depends on:
- Gleaning insights from patient data and external data sets to make good decisions
- Having data interoperability to allow permissioned data-sharing
- Presenting an LHR (Longitudinal Healthcare Record) for a patient that can be supplemented by the patients themselves using their personal/wearable data to enhance data insights for providers
- Having easy-to-use data-driven workflows for different entities in the healthcare ecosystem
- Adhering to interoperability standards for data-sharing, and
- An infrastructure that has flexible data engineering, data processing, permissioned data sharing and is data-query enabled for large data sets
By leveraging data at scale that is digitized and can be queried, healthcare organizations can promote evidence-based medicine, reduce or eliminate inequities, optimize care pathways, streamline workflows for different entities, and proactively identify and address gaps in the care of patients. But while VBC is best suited to achieve these objectives, healthcare organizations won’t experience the full benefits of that payment model if data issues are not addressed.
Formidable data challenges
A number of unresolved issues have made it difficult for healthcare organizations to fully utilize data. These include:
Unstructured data. The vast majority of data in electronic health records (EHRs) – at least 80%, according to industry estimates – is unstructured. Unstructured health data includes images, audio, video, charts, notes, faxes, freeform text, and CLOBs (Character Large Objects, or large blocks of encoded text stored in a database). Unstructured data rarely is digitized and combined with other forms of data sets. As a result, unstructured data provides little or no value to providers, health systems, and patients – despite the wealth of useful and relevant information contained within.
Lack of adherence to Data Standards. Existing data standards (HL7, x12 EDI, FHIR, NCPDP, CCLF, CCDA, etc.), are not always adhered to by different organizations, leaving a lot of custom integration work to be done. In addition, data standards are not present for a lot of patient datasets (devices and wearables, SDoH data, and external publicly available datasets, for example).
Insufficient use of external data sets. When combined with transactional and clinical data sets, external data (such as those shared by community-based organizations, and the ones available from WHO, CDC, Johns Hopkins, etc.) can provide actionable insights for providers and health plans to proactively address Social Determinants of Health (SDoH) and other factors that impact patient access to care and clinical outcomes.
No real-time or near real-time data. It currently isn’t possible to access a patient longitudinal whole health record across systems or payment information in real time. This complicates point-of-care decision-making and creates delays in the revenue cycle.
Inadequate infrastructure. Most healthcare organizations lack an IT infrastructure that can support a “network of networks” model.
Data redundancy. Data duplication problems are far too common today, even within the same data store, and different EMPI (Enterprise Master Patient Index) algorithms are used to tie those records together.
The complexity of patient data sets
Patient data falls into 18 different categories or sets. These data sets are:
- Immunity tests
- Disease registry
- Demographics data
- Employment
- Claims & remittance data
- Pharmacy data
- Eligibility & benefits data
- Clinical data (Notes, Charts, X-Ray, MRI, Radiographs, etc.)
- Financial data (from Banks for HC loans, AR Reports, Patient Responsibility from Claims)
- IOT/Wearables/Sensors data
- DNA/Genome data
- Schedule/Referral data
- SDoH data
- Surveys
- Consent management processes
- Notifications and alerts – Communication protocols
- Clinical trials data
- External summary data sources for analysis (WHO, CDC, Johns Hopkins, etc.)
These data sets are spread across different systems. Some need to be digitized and combined with structured and external data sets to complete the whole health picture for patients.
Applying AI/ML to digitize data
Technologies like Artificial Intelligence (AI) and Machine Learning (ML) play a major role in data digitization, prediction analytics and interoperability of digital healthcare data. AI and ML facilitate better automation of tasks and decision-making processes since data-driven insights are needed to automate processes and require digitized data.
Data digitization and integration of that data with structured and external data sets that offer a 360-degree view of the patient can provide actionable insights to providers, payers, and patients. AI coupled with ML algorithms in a well-designed data engineering framework that supports bidirectional integration between systems are necessary to make this a reality.
When it comes to data digitization, AI technologies like NLP (Natural Language Processing) and computer vision help with the process. NLP supports speech-to-text and vice versa, document and data conversions, patient notes, processing of unstructured data, and query support systems. Computer vision includes augmented reality (AR), virtual reality (VR), telehealth, and digital radiology.
Machine Learning algorithms facilitate more accurate detection of errors in billing and coding, leading to reduced claims denials. ML algorithms are also used for optimization of the supply chain for pharmaceuticals.
Deep learning and cognitive computing tools accelerate the processing of huge data sets, helping to inform precise and comprehensive risk forecasting and providing recommended actions that improve patient outcomes.
A flexible and scalable data infrastructure
A robust data engineering framework is essential to ensuring robust patient LHRs. Since data standards do not exist for all the different data sets mentioned above, a data engineering framework must be able to:
- Process both standard (HL7, FHIR, etc.) and non-standard data sets
- Process external data sets (such as those recommended by the CDC, Johns Hopkins, and WHO)
- Support unstructured data
- Implement a data digitization process that tags and amalgamates this data with the rest of the data while using proper categorization
- Deploy an EMPI algorithm to tie disparate patient data records into a unified patient LHR
- Utilize APIs both to expose this data using DaaS (Data as a Service) and in the platform infrastructure through a Platform as a Service (PaaS)/Software as a Service (SaaS) model running on a modern application stack that offers microservices
This underlying data infrastructure makes it possible to digitize data, synthesize data sources of different kinds, address their inconsistencies, help identify errors or misreporting, and seamlessly integrate credible new feeds. It can serve up different forms of applications in different ways. This could be done via a series of APIs under a DaaS model in which the partners/clients can pull in data and utilize it within their existing infrastructures. It also can be accomplished through a PaaS model where a set of microservices exposes the different data sets to build out different workflow-based applications or enhance existing applications. And applications can be used in a traditional SaaS model in which preconfigured workflow-based apps are built on top of these microservices for end users. Integration of such applications across the partner continuum can be achieved easily through single sign-on (SSO) to make the end-user experience seamless.
An example of such an infrastructure is depicted in Figure 1.
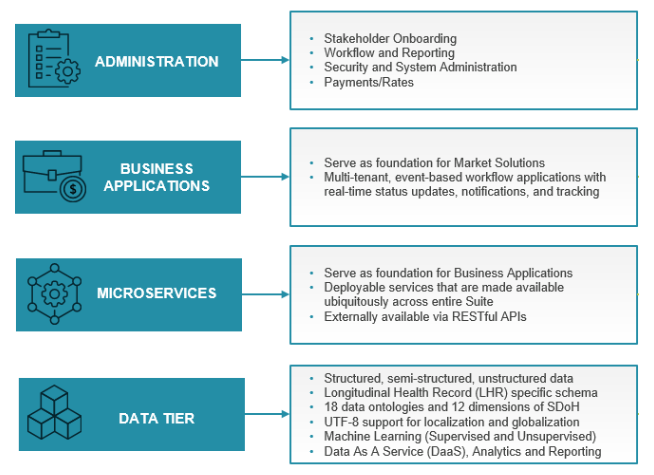
Figure 1: Layered Platform Architecture makes use of the robust data engineering framework to build critical healthcare applications.
Conclusion
Leveraging digitized data enables healthcare organizations to improve patient and population outcomes, reduce health inequities, streamline workflows, and control costs. Applying AI and ML within a robust data architecture will allow healthcare organizations to build collaborative care networks that will transform how healthcare is delivered.