
 By Dr. Pawan Jindal, Founder, MyMipsScore
By Dr. Pawan Jindal, Founder, MyMipsScore
Twitter: @MyMipsScore
In a previous blog on HL7® FHIR® and MIPS, I reviewed the basics of FHIR and how it can be leveraged to design a robust reporting platform that can go way beyond supporting MIPS. The key differentiator of FHIR from any previous standards used in the healthcare is the portability of FHIR “resources”. As outlined in the blog, this granular approach to storing and consuming healthcare data opens up many more new opportunities as compared to the traditional document-based methods.
However, this approach also presents some challenges. A single patient encounter creates multiple new FHIR resources. It may also update a number of existing resources. A diagnosis unrelated to the current illness such as flu might have been added during the last encounter and might need to be updated to “resolved”. A lab order might need to be updated with the results. There might also be situations where the data has to be deleted. An EHR has to implement the functionality to monitor and push these changes for all the FHIR resources it supports. That is a lot of work to get started with supporting FHIR.
Don’t let perfect be the enemy of good enough!
EHRs will need to support a set of public API standards as part of the 2015 Edition Certification. Although, it is recommended to use FHIR for those, it is not a requirement. To meet the certification requirements, many EHRs are implementing an approach where they just push a new C-CDA to the API every time any data in a patient record is updated. This approach, while not perfect, meets the requirements. However, with a little more planning and the magic of Azure Cosmos DB, this approach can be extended to support a full FHIR infrastructure. Let me show you how.
The EHRs already have the functionality to create a C-CDA. Using the US-Core Implementation Guide from FHIR, this can easily be updated to support creating a FHIR Bundle from the EHR. A FHIR Bundle is a container of multiple FHIR resources. In this scenario, each FHIR bundle becomes a container with one patient resource and one resource each for all the other entries in C-CDA (see image below). Note that the EHR can also add other resources to the bundle that are not available through a C-CDA. This bundle can then be pushed to the FHIR server as a single bundle of type “Document”. The bundle is stored as it is with all the resources in it. Every time any information is updated in the patient chart, an updated bundle is uploaded to the server. The process can be streamlined to run batch uploads at end of day.
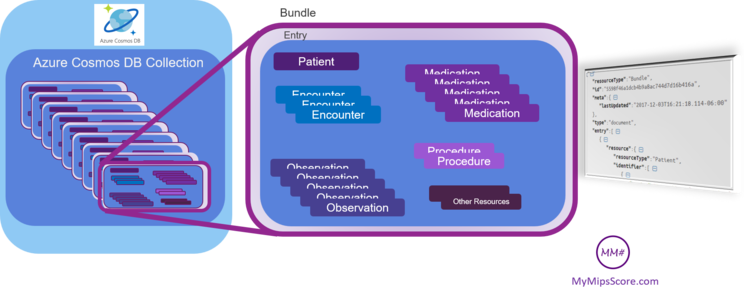
The requirement for the EHR to implement every method for every resource may not be feasible for every EHR. This approach makes it really simple to integrate and keep the data in sync between an EHR and FHIR server. However, is this truly a FHIRy implementation anymore? FHIR requires every single resource within that patient bundle to be available as an individual resource. So we should be able to retrieve every single resource like encounter or observation separately. This approach restricts us to only retrieving the patient as a bundle?
This is where Microsoft® Azure Cosmos DB comes in. First of all it is important to understand that FHIR requirement is to retrieve individual resources, not to store them. With Azure Cosmos DB, we can store the complete bundle as a single JSON document in a collection (see image). However, Azure Cosmos DB will index all the data in the document bundle including all the resources. This all happens out of the box. What that means is that we can (very easily) write a query to retrieve any of those resources individually from within a bundle. Azure Cosmos DB provides SDKs and samples in multiple programming languages that show how to do that. For instance, we can write a query to search for encounters across patients (document bundles) in a certain date range as required for quality reporting. All the logic to implement the FHIR API Get Methods for search can be actually implemented in the API while the data remains stored as a bundle. For a FHIR API consumer, it works just like any other FHIR implementation. It is important to mention that although not required in this scenario, it is possible to also implement updates/deletes any of the resources individually within any of the bundles.
Infinite indexing is just one of the features that makes Azure Cosmos DB a perfect fit for implementing a FHIR server. Azure Cosmos DB unique keys can help manage the resource ids within the bundle. If you are looking to implement a FHIR server, you should definitely check out Azure Cosmos DB.
This article was originally published on MyMipsScore and is republished here with permission.