

Rachel Podczervinski, MS, RHIA, Senior Vice President, Harris Data Integrity Solutions
LinkedIn: Rachel Podczervinski
Julie A. Pursley, MSHI, RHIA, CHDA, FAHIMA, Director of Industry Relations
LinkedIn: Julie A. Pursley
LinkedIn: Harris Data Integrity Solutions

Trust is critical in healthcare, not only trust between patients and providers but also trust in the health information used to make clinical decisions. Health information must be accurate, reliable, and complete. Unfortunately, data is inherently dirty. AHIMA estimates that 5-10% of patient records are duplicates, and some hospitals report duplicate rates as high as 22%. Meanwhile, one study found that 50% of patient notes are duplicated.
Even the most advanced AI-enabled automation technologies can’t fully resolve incorrect or incomplete duplicate patient records and other integrity issues. Matching algorithms can reduce human error, enhance care quality, and minimize the risk of misidentification, misdiagnoses, and improper or duplicative treatment. However, today’s EHRs lack sufficiently advanced matching algorithms, as their effectiveness depends on the underlying technology platform.
What is needed are what we call Caring Algorithms© that deploy AI and human intervention together to make and review matching decisions.
What are Caring Algorithms?
Caring Algorithms adhere to an AI governance framework that prioritizes safeguards and promotes ethical usage. They can accurately identify individuals and support fair and unbiased identity decisions across diverse patient populations.
Most importantly, Caring Algorithms incorporate a human-in-the-loop review mechanism for those matches where the algorithm is not 100% certain. This recognizes both the limitations of automated algorithms and the potential for automation to introduce gaps in patient identification that can affect patient safety and care coordination.
Ideally, the human-in-the-loop review mechanism leverages a variety of tools beyond the matching algorithm that can help validate simplistic discrepancies. These include rules targeting specific matching elements, data standardization tools, and third-party tools that provide historical demographics (e.g., names, addresses, and phone numbers from credit institutions and public utilities).
In fact, a recent study conducted by Harris Data Integrity Solutions highlights how initial decisions made by third-party data can change when human-in-the-loop is incorporated into the workflow. The study analyzed 137,080 pairs (two patient records) of potential duplicates and found:
- Harris DIS needed to change the third-party remediation decision in 9.1% of the pairs.
- Of “yes” decisions, 7.2% required changes, as did 2% of “no” decisions.
- Not changing the third-party decision would have created 512 (0.4%) overlays.
- Changes from “no” to “yes” involved 2,490 pairs (1.8%).
These findings clearly indicate that the presence of a human-in-the-loop oversight mechanism, along with Caring Algorithms, is vital to restoring and retaining data integrity.
Curing Complex Discrepancies
Clear boundaries are essential for navigating the complexity of data discrepancies and their potential resolution, including the number of details required to validate identity when using these tools.
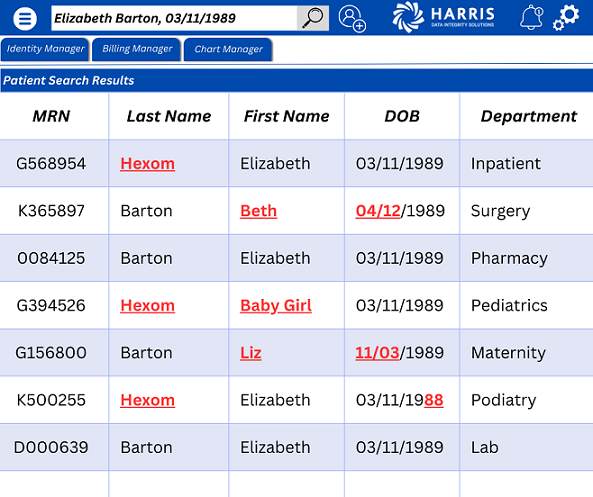
Sometimes discrepancies are not simple to remediate, for example, when multiple records could belong to a single patient. In this example, fictitious patient Elizabeth could potentially be seen by eight specialties within a single organization. Her demographics were captured erroneously in some situations, while in others she may have provided variations of her full legal name.
Some of these discrepancies can be resolved with little effort. However, depending on the type of clinical information that exists in the patient record, there may not be enough information to perform a merge confidently. Some records may require extensive research, including pediatric records, blood work, and surgical records.
For complex discrepancies, we recommend a “5 elements to a YES” approach. The “Last,” “First,” “Date of Birth,” “Gender,” and “SSN” may determine a match unless there are no other concerning nuances, such as a materially different name in the alias field or the mother’s maiden name field.
When remediating complex discrepancies, it may be helpful to differentiate between two types of duplicates:
- Standard duplicate records, defined as patients with two or more assigned records in a single system, typically exhibit more data discrepancies because they were created with demographics that could not be confidently identified in the existing master patient index (MPI).
- Crossover records, when a patient has two or more assigned records across multiple systems (not initially created in error), typically have a lower rate of data discrepancies available to prove a match.
Crossovers are typically seen when organizations acquire new facilities that service a similar patient population. As merger and acquisition rates continue to grow, so will the need for MPI data conversion strategies.
A Caring Environment
While automation can reduce the need for human intervention, it cannot completely replace it.
Overlooking its limitations and failing to establish clear boundaries and oversight can leave critical gaps. These gaps can be addressed through effective AI governance, human-in-the-loop components, and AI-driven tools designed to resolve discrepancies and ensure accurate data validation.