
 By Ashish Jha
By Ashish Jha
Twitter: @ashishkjha
In July the investigative journalists at ProPublica released an analysis of 17,000 surgeons and their complication rates. Known as the “Surgeon Scorecard,” it set off a firestorm. In the months following, the primary objections to the scorecard have become clearer and were best distilled in a terrific piece by Lisa Rosenbaum. As anyone who follows me on Twitter knows, I am a big fan of Lisa –she reliably takes on health policy groupthink and incisively reveals that it’s often driven by simplistic answers to complex problems.
So when Lisa wrote a piece eviscerating the ProPublica effort, I wondered – what am I missing? Why am I such a fan of the effort when so many people I admire– from Rosenbaum to Peter Pronovost and, most recently, other authors of a RAND report – are highly critical? When it comes to views on the surgeon scorecard, reasonable people see it differently because they begin with a differing set of perspectives. Here’s my effort to distill mine.
What is the value of transparency?
Everyone supports transparency. Even the most secretive of organizations call for it. But the value of transparency is often misunderstood. There’s strong evidence that most consumers haven’t, at least until now, used quality data when choosing providers. But that’s not what makes transparency important. It is valuable because it fosters a sense of accountability among physicians for better care. We physicians have done a terrible job policing ourselves. We all know doctors who are “007s” – licensed to kill. We do nothing about it. If I need a surgeon tomorrow, I will find a way to avoid them, but that’s little comfort to most Americans, who can’t simply call up their surgeon friends and get the real scoop. Even if patients won’t look at quality data, doctors should and usually do.
Data on performance changes the culture in which we work. Transparency conveys to patients that performance data is not privileged information that we physicians get to keep to ourselves. And it tells physicians that they are accountable. Over the long run, this has a profound impact on performance. In our study of cardiac surgery New York, transparency drove many of the worst surgeons out of the system – they moved, stopped practicing, or got better. Not because consumers were using it, but because when the culture and environment changed, poor performance became harder to justify.
Aren’t bad data worse than no data?
One important critique of ProPublica’s effort is that it represents “bad data,” that its misclassification of surgeons is so bad that it’s worse than having no data at all. Are ProPublica’s data so flawed that they represent “bad data”? I don’t think so. Claims data reliably identify who died or was readmitted. ProPublica used these two metrics – death and readmissions due to certain specific causes – as surrogates for complications. Are these metrics perfect measures of complications? Nope. As Karl Bilimoria and others have thoughtfully pointed out – if surgeon A discharges patients early, her complications are likely to lead to readmissions whereas as surgeon B, who keeps his patients in the hospital longer will see the complications in-house. Surgeon A will look worse than Surgeon B while having the same complication rate. While this may be a bigger problem for some surgery compared to others, the bottom line is that for the elective procedures examined by ProPublica, most complications are diagnosed after discharge.
Similarly, Peter Pronovost pointed out that if I am someone with a high propensity to admit, I am more likely to readmit someone with a mild post-operative cellulitis than my colleague, and while that might be good for my patients, I am likely to be dinged by ProPublica metrics for the same complication. But this is a problem for all readmissions measures. Are these issues limitations in the ProPublica approach? Yes. Is there an easy fix that they could apply to address either one of them? Not that I can think of.
But here’s the real question: are these two limitations, or any of the others listed by the RAND report, so problematic as to invalidate the entire effort? No. If you needed a surgeon for your mom’s gallbladder surgery and she lived in Tahiti (where you presumably don’t know anyone) – and Surgeon A had a ProPublica “complication rate” of 20% and surgeon B had a 2% complication rate, without any other information, would you really say this is worthless? I wouldn’t.
A reality test for me came from that cardiac surgeon study I mentioned from New York State. As part of the study, I spoke to about 30 surgeons with varying performance. Not one said that the report card had mislabeled a great surgeon as being a bad one. I heard about how the surgeon had been under stress, or that transparency wasn’t fair or that mortality wasn’t a good metric. I heard about the noise in the data, but no denials of the signal. In today’s debate over ProPublica, I see a similar theme: lots of complaints about methodology, but no evidence that the results aren’t valuable.
But let’s think about the alternative. What if the ProPublica reports are so bad that they have negative value? While I think this is not true – what should our response be? It should create a strong impetus for getting the data right. When risk-adjustment fails to account for severity of illness, the right answer is to improve risk-adjustment, not to abandon the entire effort. Bad data should lead us to better data.
Misunderstanding the value of p-values and confidence intervals
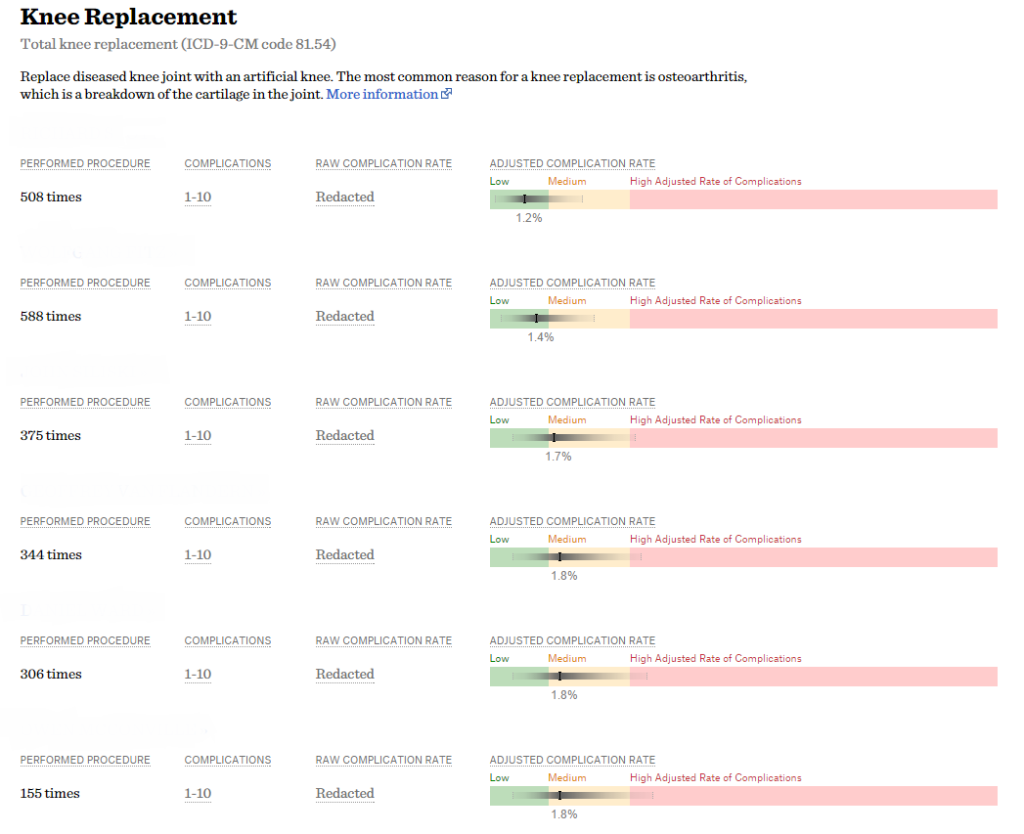
An example of the confidence intervals displayed on the Surgeon Scorecard.
Another popular criticism of the ProPublica scorecard is that its confidence intervals are wide, a line of reasoning which I believe misunderstands p-values and confidence intervals. Let’s return to your mom, who lives in Tahiti and still needs gallbladder surgery. What if I told you that I was 80% sure that surgeon A was better than average, and I was 80% sure that surgeon B was worse than average. Would you say that is useless information? Because the critique – that the 95% confidence intervals in the Propublica reports are wide – requires that we be 95% sure about an assertion to reject the null hypothesis. That threshold has a long historical context and is important when the goal is to not make a type 1 error (don’t label someone as a bad surgeon unless you are really sure he or she is bad). But if you want to avoid a type 2 error (which is what patients want – don’t get a bad surgeon, even if you might miss out on a good one), a p-value of 0.2 and 80% confidence intervals look pretty good. Of course, the critique about confidence intervals comes mostly from physicians who can get to very high certainty by calling their surgeon friends and finding out who is good. It’s a matter of perspective. For surgeons worried about being mislabeled, 95% confidence intervals seem appropriate. But for the rest of the world, a p-value of 0.05 and 95% confidence intervals is way too conservative.
A final point about the Scorecard – and maybe the most important: This is fundamentally hard stuff, and ProPublica deserves credit for starting the process. The RAND report outlines a series of potential deficiencies, each of which is worth considering – and to the extent that it’s reasonable, ProPublica should address them in the next iteration. That said – a key value of the ProPublica effort is that it has launched an important debate about how we assess and report surgical quality. The old way – where all the information was privileged and known only among physicians – is gone. And it is not coming back. So here’s the question for the critics: how do we move forward constructively – in ways that build trust with patients, spur improvements among providers, and don’t hinder access for the sickest patients? I have no magic formula. But that’s the discussion we need to be having.
Disclosure: In the early phases of the development of the Surgeon Scorecard, I was asked (along with a number of other experts) to provide guidance to ProPublica on their approach. I did, and received no compensation for my input.
About the Author: Dr. Ashish K. Jha is a practicing Internist physician and a health policy researcher at the Harvard School of Public Health. This article was originally published on his blog, An Ounce of Evidence.